import requests
from bs4 import BeautifulSoup
url = 'https://skymin02.tistory.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text,"html.parser")
print(soup)
코드 분석
모듈을 불러오는 작업 : import, from bs4 import Beautifulsoup
(처음에 import beautifulsoup를 했다가 안되서 검색을 통해서 다르게 해야한다는 걸 알았다.)
html 정보를 불러오는 작업 : requests.get(url)
html 정보를 요소, 속성, 텍스트로 분류 하는 작업을 parser 라고 생각하면 된다.
*html : 일종의 문법으로 웹페이지를 만든 정보 집합체
(한 페이지 넘는 내용을 이미지로 변환하는 느낌으로 생각하면 편하다)
plus).아래 처럼 쓰면 검색하고자하는 사이트에 요청이 비정상적일 때 무슨 오류인지 알 수 있다.
import requests
from bs4 import BeautifulSoup
url = 'https://skymin02.tistory.com/'
r = requests.get(url)
if r.status_code == 200:
soup = BeautifulSoup(r.text,"html.parser")
print(soup)
else :
print(r.status_code)
원하는 html 요소 찾기
웹 페이지 상에서 내가 어떠한 부분을 가져오려는 행위를 할 때 웹 페이지 상에서 F12를 누르면 개발자 모드가 뜨는데
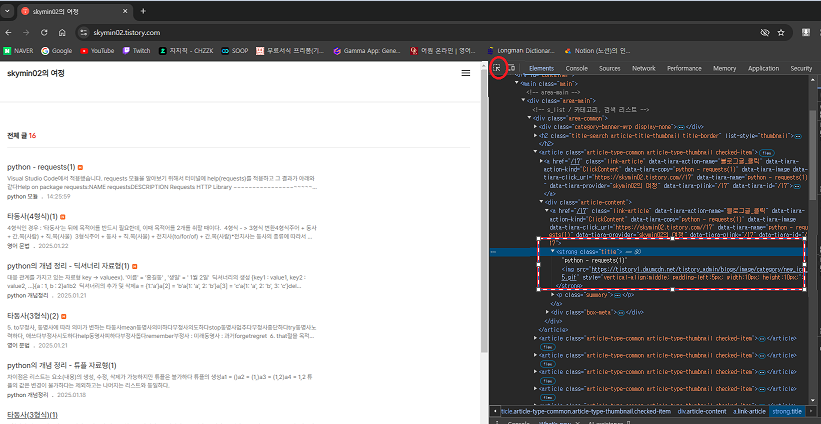
빨간원을 누르고 내가 원하는 요소(python - requests(1))를 선택하면 옆에 빨간색 박스처럼 보인다.
내가 원하는 요소를 가져올 수 있다.

위 그림처럼 copy - selector 누르면 자동으로 복사가 되고 이를 가지고 제목만을 가져오는 것을 코딩을 짠다면
import requests
from bs4 import BeautifulSoup
r = requests.get(url)
if r.status_code == 200:
soup = BeautifulSoup(r.text,"html.parser")
title = soup.select_one('#container > main > div > div.area-common > article:nth-child(3) > div')
print(title.get_text())
else :
print(r.status_code)
결과 값으로
python 모듈
14:25:59이런식으로 나온다.
plus).
print(tilte)를 하게 되면 모든 문자열이 출력이 된다.
| find | 태그 추출 |
| find_all | |
| class | |
| id |
'python 모듈' 카테고리의 다른 글
| python - requests(1) (0) | 2025.01.23 |
|---|